1. 異常検知技術の全体概要
異常検知の定義とその重要性
異常検知(Anomaly Detection)は、データの中から通常のパターンとは異なる異常なパターンを特定する技術です。この技術は、製造業での不良品検出、サイバーセキュリティにおける侵入検知、医療における病気の早期発見など、様々な分野で活用されています。異常は通常のパターンとは異なるため、事前に定義されたルールではなく、機械学習や深層学習を用いて学習することが求められます。
MVTec ADデータセットの役割とその影響
MVTec ADデータセットは、製造業における異常検知のために特化して設計されたデータセットです。このデータセットには、様々な工業製品の画像が含まれており、正常な製品と異常な製品の違いを学習するための重要なリソースとなっています。MVTec ADは、高精度な異常検知モデルの開発を促進するだけでなく、新しい手法の評価基準としても広く使用されています。

近年の異常検知技術のトレンド
近年、異常検知技術は大きく進化し、より高度で効率的な手法が次々と登場しています。特に、ディープラーニング技術の進展に伴い、異常検知の精度や速度が飛躍的に向上しました。以下に示す最新の手法は、特にMVTec ADデータセットを用いた研究において、優れた性能を示しています。
これまでの技術では、教師あり学習が主流でしたが、近年では、ラベルのないデータから異常を検知する教師なし学習や半教師あり学習の手法が注目されています。また、軽量化されたモデルによるリアルタイム異常検知や、異常の正確な位置を特定する異常局所化技術も発展しています。
2. SPADE: サブイメージ異常検知
SPADEの技術的概要
SPADE(Sub-Image Anomaly Detection with Deep Pyramid Correspondences)は、異常検知のための手法として、深層学習を用いてサブイメージの対応を学習するアプローチです。この手法は、正常な画像内のパッチ(部分画像)間の対応関係をモデル化することで、異常を検出します。
SPADEの主な特徴は、画像を複数のスケールで解析する深層ピラミッド構造を採用していることです。これにより、異なる解像度での異常を効果的に捉えることができます。また、画像の各領域の特徴を深層特徴空間で対応付けることで、微細な異常も検出可能です。
Deep Pyramid Correspondencesの利用方法
Deep Pyramid Correspondencesは、画像を複数の解像度で分析し、それぞれの解像度における画像パッチ間の関係を学習する手法です。具体的には、以下のプロセスで異常を検知します。
-
特徴抽出: 入力画像から多層の特徴を抽出します。これにより、低レベルから高レベルの特徴が得られます。
-
ピラミッド対応付け: 異なるスケールの特徴マップを比較し、正常画像における対応関係を学習します。この対応関係を基に、テスト画像内の異常を特定します。
-
異常スコアの計算: テスト画像の各パッチについて、正常パッチとの対応関係のズレを計算し、そのズレを異常スコアとして評価します。
SPADEは、特に製造業での欠陥検出において、細かい欠陥を見逃さない高い検出能力を発揮します。
MVTec ADにおける成果
SPADEはMVTec ADデータセットにおいて、優れた性能を示しています。具体的には、高精度での異常検知が可能であり、製品の微細な欠陥を見つけ出すことに成功しています。従来の手法と比較しても、SPADEは高い異常検出精度と局所化性能を実現しており、多くの研究者から注目を集めています。

3. Gaussian-AD: 正常データの分布モデリング
Gaussian-ADの基本的なアプローチ
Gaussian-AD(Modeling the Distribution of Normal Data in Pre-Trained Deep Features for Anomaly Detection)は、事前学習されたディープラーニングモデルの特徴を利用して、正常データの分布をガウス分布としてモデル化し、異常検知を行う手法です。この手法の主な目的は、正常データの統計的特性を利用して異常を検出することです。
具体的には、事前学習されたモデル(例えばResNetやVGGなど)を用いて画像の特徴を抽出し、その特徴を基に正常データの分布をガウス分布として近似します。テストデータがこの正常分布からどれほど外れているかを計算することで、異常スコアを算出します。
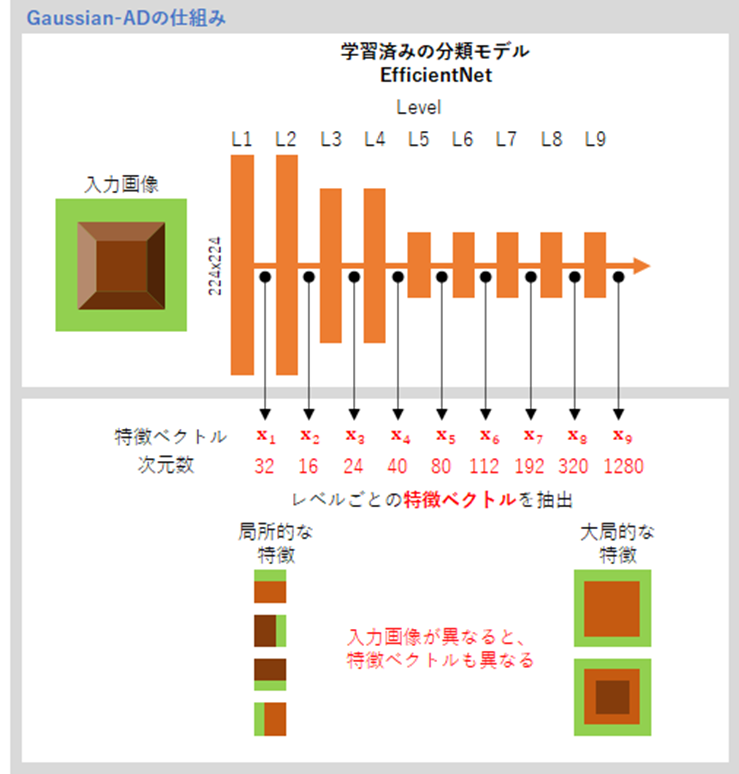
Pre-Trained Deep Featuresの利用
Gaussian-ADでは、事前に学習された深層モデルの特徴を用いることで、ラベルなしのデータに対しても効果的に異常を検知できます。以下の手順で異常検知を行います。
- 特徴抽出: 正常画像を事前学習された深層モデルに入力し、特徴ベクトルを抽出します。この特徴ベクトルは、画像の高次元な表現を含んでいます。
- ガウス分布のモデリング: 抽出された正常データの特徴ベクトルに基づいて、平均ベクトルと共分散行列を計算し、これらを用いて正規分布(ガウス分布)をモデル化します。
- 異常スコアの算出: テスト画像を同じ深層モデルに入力して特徴ベクトルを抽出し、正常分布とのマハラノビス距離を計算します。この距離が大きいほど異常と判断されます。

出典:https://qiita.com/makotoito/items/39bc64d30ce49a9edad8
手法の強みと弱み
強み:
- 汎用性: 事前学習されたモデルを利用するため、異なる種類のデータに対しても適用可能です。
- 効率性: 深層学習モデルの特徴を活用することで、異常検知の精度が向上します。
弱み:
- モデル依存性: 特徴抽出に用いるモデルの性能に依存するため、事前学習モデルの選択が重要です。
- 非線形性の制約: ガウス分布の仮定が常に正確であるとは限らず、複雑なデータに対しては制約が生じる可能性があります。
Gaussian-ADは、特に事前学習された深層モデルを活用することで、ラベルなしデータに対する異常検知を効果的に行う手法として注目されています。
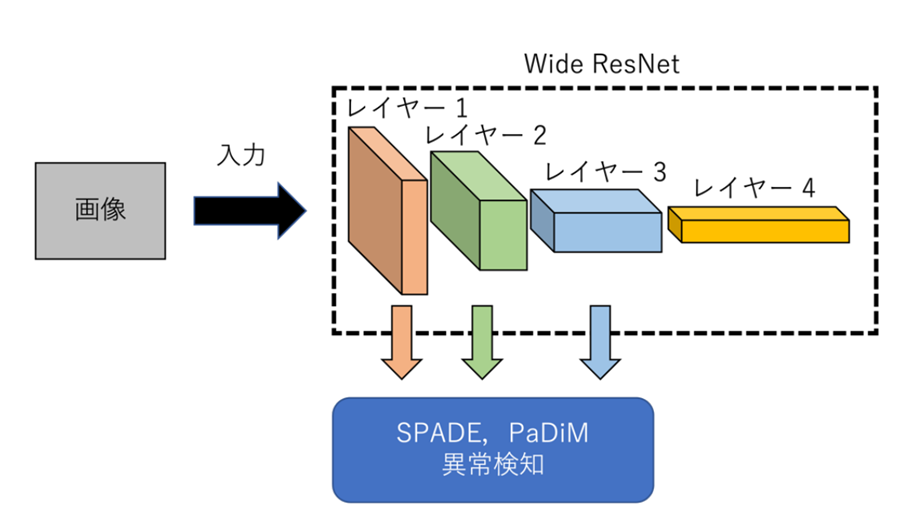
4. PaDiM: パッチ分布モデリングフレームワーク
PaDiMのアーキテクチャと設計思想
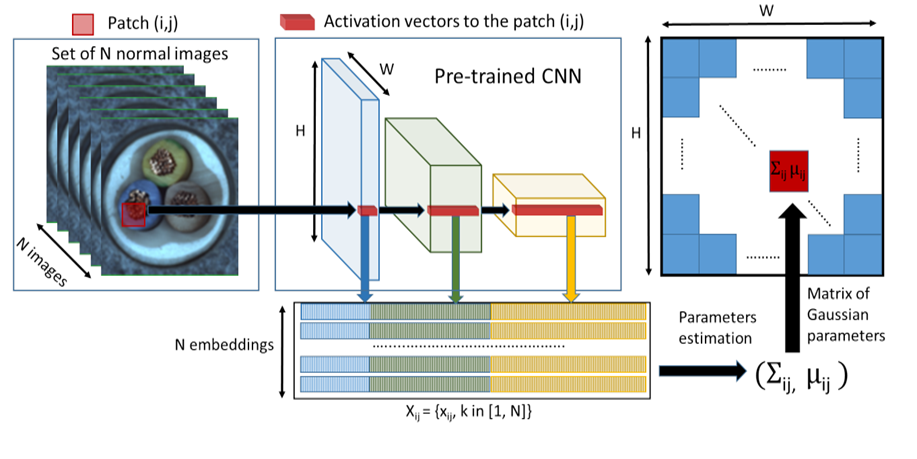
PaDiM(Patch Distribution Modeling)は、画像をパッチ(小領域)に分割し、それぞれのパッチの分布をモデル化することで異常を検知する手法です。このアプローチは、特に異常局所化の精度を向上させるために設計されています。
PaDiMの基本的なアイデアは、各パッチの特徴を抽出し、その特徴を正規分布としてモデル化することです。このモデルは、正常データのパッチごとの特徴分布を学習し、新しいデータが正常か異常かを判断する際に、その分布からどれだけ逸脱しているかを評価します。
異常検知と局所化における成功
PaDiMは、異常検知だけでなく、異常の局所化にも優れた性能を発揮します。以下のプロセスで異常を検知し、局所化します。
-
特徴抽出: 画像をパッチ単位に分割し、事前学習されたCNN(例えばResNetやEfficientNetなど)を用いて各パッチの特徴を抽出します。
-
パッチの分布モデリング: 各パッチの特徴ベクトルを用いて、正規分布をモデル化します。これにより、各パッチの平均と共分散行列を学習します。
-
異常スコアの計算: テスト画像に対して同様に特徴を抽出し、各パッチが正常分布からどれだけ逸脱しているかを評価します。この逸脱度を異常スコアとして算出します。
-
異常局所化: パッチごとの異常スコアを用いて異常の位置を特定し、異常マップを生成します。この異常マップは、どの領域が異常であるかを視覚的に示します。
比較分析: PaDiM vs 他手法
PaDiMの強み:
- 高精度な異常局所化: パッチ単位での分析により、微細な異常も正確に検出可能です。
- 事前学習モデルの活用: 既存のCNNモデルを用いることで、特徴抽出の効率と精度を高めています。
他手法との比較:
- SPADEとの比較: SPADEは多層のピラミッド構造を用いてスケールごとに異常を検出しますが、PaDiMはパッチ単位の局所化に優れています。
- Gaussian-ADとの比較: Gaussian-ADはデータ全体の分布をモデリングしますが、PaDiMはパッチごとの詳細な分布を捉えるため、異常の局所化に優れています。
PaDiMは、特に製造業などの異常検知が重要な分野において、その高精度な異常検出と局所化能力で注目されています。
5. PatchCore: 工業用異常検知における完全リコールの追求
PatchCoreの目標と手法
PatchCoreは、「完全リコール(Total Recall)」を目指して開発された異常検知手法です。この手法は、特に製造業などの工業用異常検知で、可能な限りすべての異常を検出することを目指しています。PatchCoreは、クエリパッチを活用し、対象の画像からパッチレベルでの異常を捉えることに重点を置いています。
PatchCoreの主な特徴は、メモリ効率の向上と検出精度の向上を両立することにあります。これは、特徴空間におけるコアセット選択と呼ばれる手法を用いることで実現されます。コアセット選択では、特徴空間から最も代表的な特徴のみを選択し、それを基に異常を検知するため、計算量を抑えつつ精度を高めることができます。
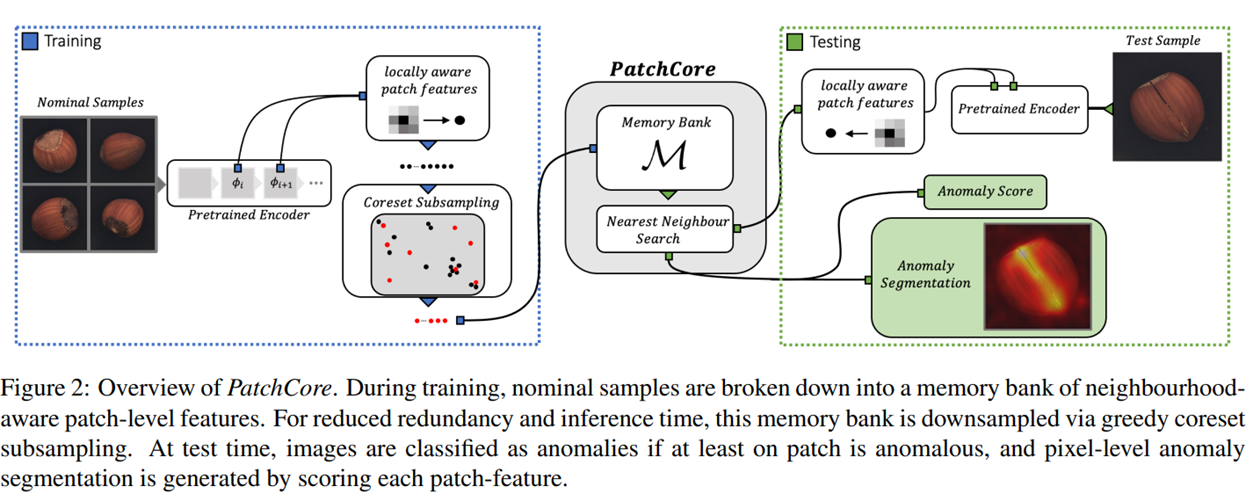
Total Recallの実現方法
PatchCoreは以下のプロセスで異常を検知し、Total Recallを実現します。
-
特徴抽出: 事前学習されたCNNを用いて画像のパッチから特徴を抽出します。これにより、各パッチが高次元空間で表現されます。
-
コアセット選択: 抽出された特徴から、最も重要な特徴だけを選択するコアセット選択を行います。これは、空間におけるデータの冗長性を排除し、メモリ使用量を削減するためです。
-
距離計算: コアセットとテストデータのパッチ間で距離計算を行い、テストデータが正常データからどれだけ逸脱しているかを評価します。異常のスコアリングにはマハラノビス距離が利用されます。
-
異常マップ生成: 各パッチの異常スコアを基に異常マップを生成し、どの領域が異常であるかを特定します。

実世界の応用事例
PatchCoreは、多くの実世界の応用事例でその効果が確認されています。特に、以下のような分野で優れた性能を発揮しています。
- 製造業: 生産ラインにおける不良品検出で、微細な欠陥を見逃さずに検出するために利用されています。
- 品質管理: 製品の品質を保証するために、製造プロセスの各ステージでリアルタイムに異常を検出します。
- セキュリティ監視: 防犯カメラ映像などで異常行動や不審者を特定する際に利用されています。
PatchCoreは、総合的な異常検知能力と効率的な計算資源の利用が評価され、多くの産業界で採用されています。
6. AutoEncoder-SSIM: 歴史的な異常検知手法の進化
AutoEncoder-SSIMの背景と目的
AutoEncoder-SSIMは、従来のオートエンコーダーを用いた異常検知手法を改良したもので、特に画像の構造を意識した損失関数としてSSIM(構造類似性指数)を導入しています。オートエンコーダーは、データを効率的に圧縮し、元のデータに復元するためのニューラルネットワークで、入力データと出力データの差分(損失)を最小化することを目指しています。
この手法の目的は、特に画像データにおいて、画像のピクセル単位の差分だけでなく、人間の視覚にとって意味のある構造情報を重視することです。これにより、画像の歪みやノイズを含めた異常をより効果的に検出します。
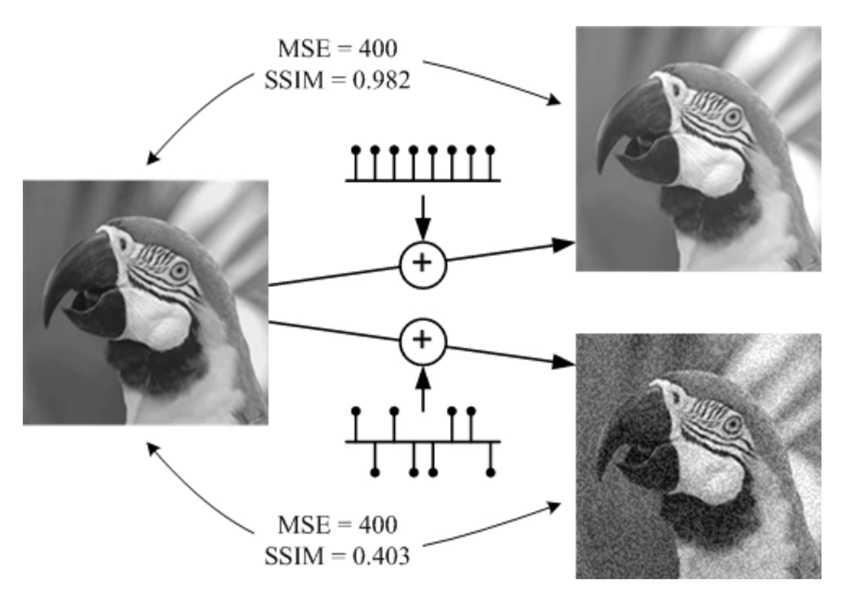
SSIMの導入による効果
SSIM(Structural Similarity Index)は、画像の明るさ、コントラスト、構造を考慮して、2つの画像間の類似性を評価する指標です。AutoEncoder-SSIMでは、復元された画像と元の画像の間でSSIMを用いて損失を計算します。この導入により、以下のような効果が得られます。
-
構造情報の重視: ピクセル単位のMSE(平均二乗誤差)だけでなく、画像の全体的な構造情報を考慮するため、異常箇所をより正確に捉えられます。
-
ノイズのロバスト性: SSIMは画像の構造を重視するため、ノイズや微細な変動に対しても頑健な異常検知が可能です。
-
視覚的な解釈: 人間の視覚に近い形で異常を評価できるため、検出結果がより直感的に理解しやすくなります。
進化した手法の有効性
AutoEncoder-SSIMは、特にMVTec ADデータセットを用いた異常検知において、その効果を実証しています。以下にその有効性を示します。
-
高精度な異常検知: オートエンコーダーとSSIMの組み合わせにより、通常のオートエンコーダー手法に比べて高い精度で異常を検出します。
-
リアルタイム応用: 計算が比較的軽量であるため、リアルタイムでの異常検知にも適用可能です。これは製造ラインやセキュリティモニタリングにおいて重要です。
-
歴史的な影響: AutoEncoder-SSIMは、異常検知の歴史において重要なステップとなり、多くの後続研究に影響を与えています。これにより、さまざまな分野での異常検知手法の開発が加速しました。

AutoEncoder-SSIMは、単なる技術的な改良にとどまらず、異常検知手法の理解と応用において新たな視点を提供しています。
7. EfficientAD: 効率的な視覚異常検知
Teacher-Studentモデルの応用
EfficientADは、異常検知において計算の効率化と精度の両立を目指した手法であり、特に教師(Teacher)-生徒(Student)モデルを利用することに特徴があります。この手法は、軽量かつ高性能な異常検知を実現するために開発されました。
Teacher-Studentモデルでは、事前に学習された大規模なTeacherモデルが示す特徴を、より小規模で計算量の少ないStudentモデルに模倣させることで、高い性能を維持しつつ軽量化を図ります。EfficientADは、以下の手順で異常を検知します。
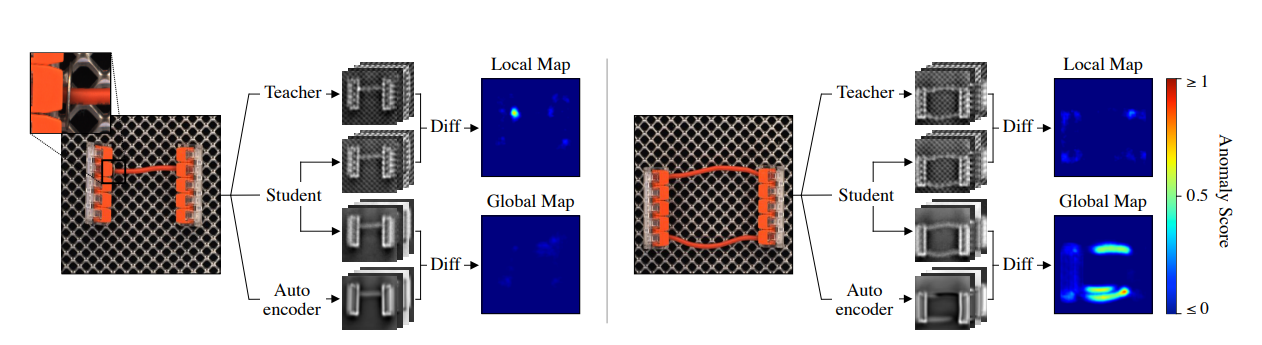
-
特徴学習: Teacherモデルに正常データを入力し、その高次元の特徴を抽出します。この特徴は、Studentモデルが模倣すべき目標となります。
-
模倣学習: Studentモデルが、Teacherモデルから抽出された特徴を再現するように訓練されます。この際、モデルの軽量化により推論速度が向上します。
-
異常検知: テストデータに対して、StudentモデルがTeacherモデルと異なる特徴を出力するかどうかを評価し、その差異を異常スコアとして計算します。大きな差異が検出された場合、それは異常と判断されます。
モデルの軽量化とその利点
EfficientADは、軽量モデルの設計により、以下の利点を提供します。
- 高速推論: Studentモデルの計算量が少ないため、リアルタイムでの異常検知が可能です。これにより、工業製品の生産ラインなどで即時の異常対応が可能となります。
- 低メモリ消費: モデルのパラメータ数が少なくなるため、メモリの消費量も削減され、組み込みシステムやモバイルデバイスでの運用が容易になります。
- 適応性: 軽量化によって、異なるアプリケーションや環境への適応が迅速に行えるようになります。
EfficientADは、MVTec ADデータセットを用いた実験において、従来の異常検知手法と比較して高い精度と効率を示しています。特に、Teacher-Studentモデルによる設計が、異常検知の分野で新たな基準を提供する可能性を示しています。

今後の異常検知
異常検知技術は、今後も様々な方向に発展していくことが期待されます。以下にそのいくつかの方向性を示します。
- ディープラーニングのさらなる活用: より高度なディープラーニングモデルの開発が進み、異常検知の精度や適用範囲が拡大していくでしょう。
- 自己学習と適応型モデル: 異常パターンの変化に対して、モデルが自動的に学習し適応する技術が重要となります。
- 異常検知とビッグデータの統合: IoTデバイスやセンサーネットワークから得られるビッグデータを活用し、リアルタイムでの異常検知を行うシステムの構築が進むでしょう。
異常検知技術の進化は、産業界や日常生活における安全性と効率性を向上させる鍵となります。今後も新しい技術やアプローチが登場し続けることが予想され、研究者やエンジニアにとって挑戦的な分野であり続けるでしょう。
参考文献
- MVTEC-AD: https://www.mvtec.com/company/research/datasets/mvtec-ad
- SPADE : https://arxiv.org/abs/2002.10445
- Gaussian-AD : https://arxiv.org/pdf/2005.14140.pdf
- PaDiM: https://arxiv.org/pdf/2011.08785.pdf
- PatchCore : https://arxiv.org/abs/2106.08265
- AutoEncoder SSIM : https://arxiv.org/abs/1807.02011
- EfficientAD:https://arxiv.org/abs/2303.14535