[技術ブログ] CLIP(Contrastive Language–Image Pre-training)の解説
TLDR
論文の題名と著者名、発行年
- Title: Learning Transferable Visual Models From Natural Language Supervision
- Authors: Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever
- Year: 2021
- Link: https://arxiv.org/abs/2103.00020
どんなもの?
この論文では、CLIP(Contrastive Language–Image Pre-training)という新しい学習手法を提案しています。これは、インターネット上から収集した4億の画像と言語ペアを使用して、自然言語の監督下で視覚モデルを学習するものです。CLIPは、テキストと画像の組み合わせを予測するタスクを通じて学習を行い、その後、テキストを用いて新しい視覚概念をゼロショットで転送することができます。
先行研究と比べてどこがすごい?
従来のコンピュータビジョンモデルは、固定されたオブジェクトカテゴリに対してトレーニングされており、ゼロショット学習が困難でした。しかし、CLIPは自然言語から学習することで、固定されたカテゴリに依存せず、幅広いタスクに対して適応可能な視覚表現を獲得できる点が優れています。また、CLIPはゼロショットで複数のタスクに転送可能であり、その精度は従来の完全監督モデルと同等、またはそれ以上の性能を示しています。
技術や手法のキモはどこ?
CLIPのキモは、画像とテキストのペアを使った対照的な事前トレーニングです。この手法では、テキストエンコーダと画像エンコーダが共同でトレーニングされ、画像とテキストの組み合わせが正しいかどうかを予測します。これにより、CLIPは広範な視覚概念を学習し、これらをテキストを使って参照または記述することができるようになります。
どうやって有効だと検証した?
CLIPは、OCRやアクション認識、地理的ローカライゼーション、細かいオブジェクト分類など30以上の異なるコンピュータビジョンタスクで検証され、その多くでゼロショットで優れた性能を発揮しました。特に、ImageNetデータセットでは、トレーニングに用いられた128万のラベル付きデータを使用せずに、ResNet-50と同等の精度を達成しました。
議論はある?
CLIPのアプローチは、データの多様性と自然言語を利用することで、従来のモデルが抱える問題、特に特定のデータセットに過剰適応する傾向を改善しています。しかし、その一方で、ゼロショット学習が全てのタスクで最適であるわけではなく、特に複雑なタスクや抽象的なタスクでは性能が劣る場合があることが指摘されています。
次に読むべき論文は?
次に読むべき論文としては、CLIPと同様の自然言語監督を用いた学習手法を取り入れた他の研究、例えば「VirTex」や「ICMLM」、「ConVIRT」といった論文が挙げられます。また、視覚表現学習やゼロショット学習に関する最近の研究動向も追うと良いでしょう。
解説記事
CLIP: 画像と言語のペアから学ぶ新たな視覚モデルの誕生
2021年に発表された論文「Learning Transferable Visual Models From Natural Language Supervision」は、視覚認識技術の新たな方向性を示す重要な研究です。この論文では、OpenAIの研究者たちが提案したCLIP(Contrastive Language–Image Pre-training)というモデルについて詳述されています。このモデルは、インターネット上から収集された4億組の画像と言語のペアを使用し、自然言語を通じて視覚モデルを学習させるという、画期的な手法です。
1. CLIPとは何か?
CLIPは、従来の視覚モデルとは異なり、固定されたオブジェクトカテゴリに依存しません。従来のモデルは、特定のカテゴリ(例えば「犬」「猫」など)に対して訓練され、それ以外のタスクに適応することが困難でした。しかし、CLIPは自然言語を利用することで、幅広い視覚概念をゼロショットで転送できる能力を持っています。
ゼロショットとは、モデルが訓練されていない新しいタスクを行う能力のことで、例えばCLIPは「宇宙ステーション」のような特定のテキストを入力すると、対応する画像を正しく識別することが可能です。この能力は、従来の完全監督型モデルと同等、もしくはそれ以上の精度を誇ります。
2. CLIPの技術的背景とその意義
CLIPの核となる技術は、対照的事前学習(Contrastive Pre-training)です。この手法では、画像エンコーダとテキストエンコーダが共同でトレーニングされ、画像とテキストの組み合わせが正しいかどうかを予測します。この対照的学習により、CLIPは多様な視覚概念を学習し、これらの概念をテキストで参照することができます。
また、CLIPは大規模なデータセットを使用して学習されており、一般的な視覚タスクにゼロショットで優れた性能を発揮することが確認されています。特に、ImageNetデータセットでのテストにおいて、CLIPは128万のラベル付きデータを使用せずに、ResNet-50と同等の精度を達成しました。
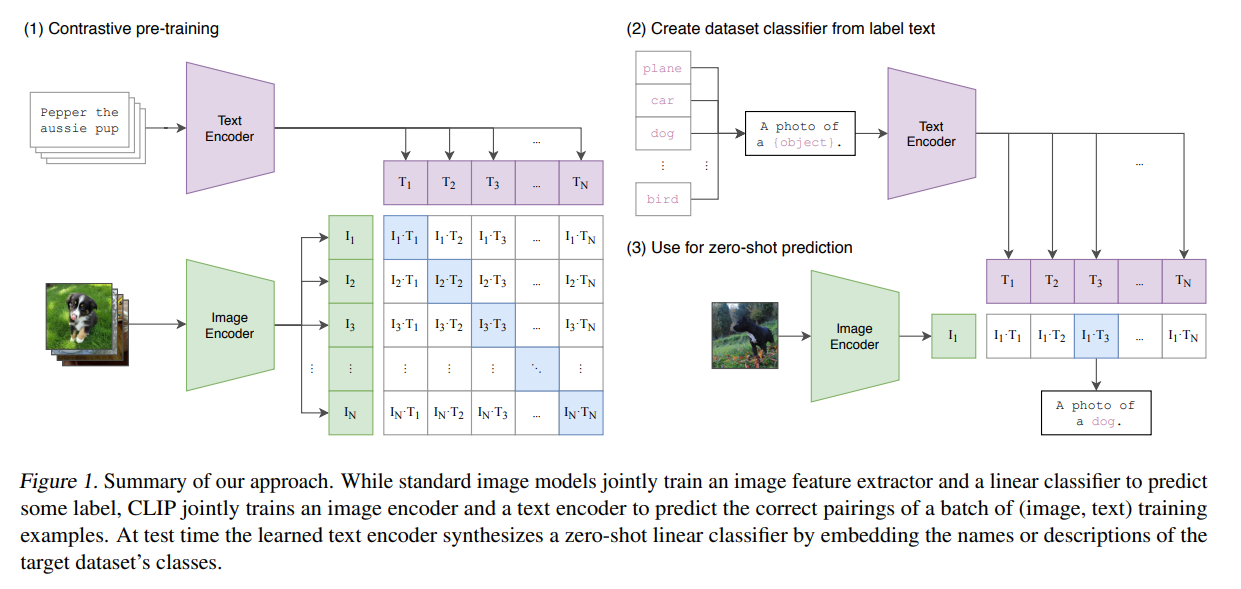
Figure 1
Description (translated): 我々のアプローチの概要。標準的な画像モデルでは、画像特徴抽出器と線形分類器を共同で訓練し、ラベルを予測する。一方、CLIPでは、画像とテキストのエンコーダを共同で訓練し、バッチ内の(画像、テキスト)のトレーニング例が正しくペアになっているかを予測する。テスト時には、学習したテキストエンコーダがターゲットデータセットのクラスの名前や説明を埋め込むことで、ゼロショットの線形分類器を合成する。
3. CLIPの優位性と限界
CLIPは、データの多様性と自然言語を利用することで、従来の視覚モデルが抱える「特定のデータセットに過剰適応する」という問題を改善しています。しかし、ゼロショット学習が全てのタスクで最適なわけではなく、特に複雑なタスクや抽象的なタスクでは性能が劣ることもあります。
また、CLIPのアプローチは、他の自然言語監督を用いた学習手法と比較しても優れており、特に「VirTex」や「ICMLM」、「ConVIRT」といった類似研究と対比して、その有効性が際立っています。
4. CLIPの将来展望
CLIPの成功は、視覚認識の新たな可能性を開き、今後の研究に大きな影響を与えることが期待されます。次に読むべき論文としては、CLIPと同様の手法を用いた研究が推奨されます。また、視覚表現学習やゼロショット学習に関する最新の研究を追うことも重要です。
この研究が示すように、自然言語から学ぶ視覚モデルの未来は非常に有望であり、さらなる発展が期待されます。
5. CLIPの技術的な詳細とそのメカニズム
CLIPは、その革新性と多用途性を支えるために、いくつかの技術的工夫を取り入れています。ここでは、CLIPがどのようにして視覚モデルを構築し、自然言語を用いてゼロショット学習を実現しているのか、具体的なメカニズムについて解説します。
5.1 対照的事前学習 (Contrastive Pre-training)
CLIPの中心的な技術は「対照的事前学習」です。この手法は、画像とテキストのペアを使ってモデルをトレーニングするもので、具体的には以下のプロセスが含まれます。
-
データペアの作成: まず、インターネットから収集された4億組の画像と言語ペアを使用します。各ペアは、「この画像に対する説明として正しいテキストはどれか」というタスクを通じて、モデルに提示されます。
-
エンコーダの学習: CLIPは、画像を処理する画像エンコーダと、テキストを処理するテキストエンコーダを持ちます。これらのエンコーダは、共同で学習され、画像とテキストが一致するかどうかを予測するために、特徴ベクトルを生成します。
-
コサイン類似度の計算: 画像とテキストのベクトルの間でコサイン類似度が計算され、ペアが正しいほど類似度が高くなるように調整されます。誤ったペアの類似度は低くなるように学習が進みます。
-
損失関数の最適化: 最後に、対照的な損失関数を用いて、モデルがペアを正しく識別できるようにトレーニングされます。具体的には、実際のペアと誤ったペアの間で類似度のギャップが最大化されるようにモデルが調整されます。
5.2 ゼロショット学習とモデルの転送
CLIPのもう一つの重要な特徴は、ゼロショットで学習結果を他のタスクに転送できる能力です。これは、CLIPが自然言語を用いて視覚概念を理解し、テキストを使って新しいタスクに適応することができるためです。
-
ゼロショット分類: 例えば、ある新しいデータセットに対して、CLIPはそのデータセットのクラスラベルをテキストとして入力し、各画像がどのクラスに属するかを予測します。このとき、CLIPは画像と各クラスラベルのテキストとの間のコサイン類似度を計算し、最も類似度の高いクラスを予測します。
-
プロンプトエンジニアリング: ゼロショット分類の精度を向上させるために、クラスラベルを単純な単語ではなく、より文脈に沿った文章に変換することが効果的です。例えば、「犬」というラベルを「犬の写真」とすることで、CLIPがテキストの意図をより正確に理解できるようになります。
5.3 CLIPのスケーリングと効率性
CLIPのトレーニングは非常に大規模であり、その効率性も重要な要素となっています。CLIPは、複数の異なるモデル(ResNetやVision Transformer)で構成されており、それぞれが異なる計算リソースを使用してトレーニングされています。
-
ResNetモデル: CLIPでは、従来のResNetアーキテクチャをベースにしたモデルが使用されていますが、効率性を向上させるためにいくつかの改良が加えられています。例えば、ResNetのプーリングレイヤーを注意メカニズムに置き換えることで、画像の特徴をより効果的に捉えられるようにしています。
-
Vision Transformer (ViT): 最近注目されているViTアーキテクチャもCLIPに採用されています。このアーキテクチャは、計算効率が高く、特に大規模データセットで優れた性能を発揮します。
CLIPのトレーニングは非常に高価な計算資源を必要としますが、それでもCLIPは、ゼロショット分類で競争力のある性能を発揮し、従来の完全監督型モデルと比較して、計算コストを大幅に削減しています。
6. 結論
CLIPは、視覚認識の新たな可能性を示す強力なモデルです。その内部メカニズムとトレーニングプロセスの詳細を理解することで、どのようにして幅広いタスクに対応し、ゼロショット学習を実現しているのかが
明らかになります。しかし、CLIPにも技術的な課題が残されており、これらを克服するためにはデータの多様化やモデルの強化が必要です。今後、CLIPのさらなる発展が期待されます。